
深入理解Android之Gradle
原文地址:http://blog.csdn.net/innost/article/details/48228651
Gradle是当前非常“劲爆”得构建工具。本篇文章就是专为讲解Gradle而来。介绍Gradle之前,先说点题外话。
一、题外话
说实话,我在大法工作的时候,就见过Gradle。但是当时我一直不知道这是什么东西。而且大法工具组的工程师还将其和Android Studio大法版一起推送,偶一看就更没兴趣了。为什么那个时候如此不待见Gradle呢?因为我此前一直是做ROM开发。在这个层面上,我们用make,mm或者mmm就可以了。而且,编译耗时对我们来说也不是啥痛点,因为用组内吊炸天的神机服务器完整编译大法的image也要耗费1个小时左右。所以,那个时侯Gradle完全不是我们的菜。
现在,搞APP开发居多,编译/打包等问题立即就成痛点了。比如:
- 一个APP有多个版本,Release版、Debug版、Test版。甚至针对不同APP Store都有不同的版本。在以前ROM的环境下,虽然可以配置Android.mk,但是需要依赖整个Android源码,而且还不能完全做到满足条件,很多事情需要手动搞。一个app如果涉及到多个开发者,手动操作必然会带来混乱。
- library工程我们需要编译成jar包,然后发布给其他开发者使用。以前是用eclipse的export,做一堆选择。要是能自动编译成jar包就爽了。
上述问题对绝大部分APP开发者而言都不陌生,而Gradle作为一种很方便的的构建工具,可以非常轻松得解决构建过程中的各种问题。
二、闲言构建
构建,叫build也好,叫make也行。反正就是根据输入信息然后干一堆事情,最后得到几个产出物(Artifact)。
最最简单的构建工具就是make了。make就是根据Makefile文件中写的规则,执行对应的命令,然后得到目标产物。
日常生活中,和构建最类似的一个场景就是做菜。输入各种食材,然后按固定的工序,最后得到一盘菜。当然,做同样一道菜,由于需求不同,做出来的东西也不尽相同。比如,宫保鸡丁这道菜,回民要求不能放大油、口淡的要求少放盐和各种油、辣不怕的男女汉子们可以要求多放辣子....总之,做菜包含固定的工序,但是对于不同条件或需求,需要做不同的处理。
在Gradle爆红之前,常用的构建工具是ANT,然后又进化到Maven。ANT和Maven这两个工具其实也还算方便,现在还有很多地方在使用。但是二者都有一些缺点,所以让更懒得人觉得不是那么方便。比如,Maven编译规则是用XML来编写的。XML虽然通俗易懂,但是很难在xml中描述if{某条件成立,编译某文件}/else{编译其他文件}这样有不同条件的任务。
怎么解决?怎么解决好?对程序员而言,自然是编程解决,但是有几个小要求:
- 这种“编程”不要搞得和程序员理解的编程那样复杂。寥寥几笔,轻轻松松把要做的事情描述出来就最好不过。所以,Gradle选择了Groovy。Groovy基于Java并拓展了Java。 Java程序员可以无缝切换到使用Groovy开发程序。Groovy说白了就是把写Java程序变得像写脚本一样简单。写完就可以执行,Groovy内部会将其编译成Javaclass然后启动虚拟机来执行。当然,这些底层的渣活不需要你管。
- 除了可以用很灵活的语言来写构建规则外,Gradle另外一个特点就是它是一种DSL,即Domain Specific Language,领域相关语言。什么是DSL,说白了它是某个行业中的行话。还是不明白?徐克导演得《智取威虎山》中就有很典型的DSL使用描述,比如:
------------------------------------------------------------------------------
土匪:蘑菇,你哪路?什么价?(什么人?到哪里去?)
杨子荣:哈!想啥来啥,想吃奶来了妈妈,想娘家的人,孩子他舅舅来了。(找同行)
杨子荣:拜见三爷!
土匪:天王盖地虎!(你好大的胆!敢来气你的祖宗?)
杨子荣:宝塔镇河妖!(要是那样,叫我从山上摔死,掉河里淹死。)
土匪:野鸡闷头钻,哪能上天王山!(你不是正牌的。)
杨子荣:地上有的是米,喂呀,有根底!(老子是正牌的,老牌的。)
------------------------------------------------------------------------------
Gradle中也有类似的行话,比如sourceSets代表源文件的集合等.....太多了,记不住。以后我们都会接触到这些行话。那么,对使用者而言,这些行话的好处是什么呢?这就是:
一句行话可以包含很多意思,而且在这个行当里的人一听就懂,不用解释。另外,基于行话,我们甚至可以建立一个模板,使用者只要往这个模板里填必须要填的内容,Gradle就可以非常漂亮得完成工作,得到想要的东西。
这就和现在的智能炒菜机器似的,只要选择菜谱,把食材准备好,剩下的事情就不用你操心了。吃货们对这种做菜方式肯定是以反感为主,太没有特色了。但是程序员对Gradle类似做法却热烈拥抱。
到此,大家应该明白要真正学会Gradle恐怕是离不开下面两个基础知识:
- Groovy,由于它基于Java,所以我们仅介绍Java之外的东西。了解Groovy语言是掌握Gradle的基础。
- Gradle作为一个工具,它的行话和它“为人处事”的原则。
三、Groovy介绍
Groovy是一种动态语言。这种语言比较有特点,它和Java一样,也运行于Java虚拟机中。恩??对头,简单粗暴点儿看,你可以认为Groovy扩展了Java语言。比如,Groovy对自己的定义就是:Groovy是在 java平台上的、 具有像Python, Ruby 和 Smalltalk 语言特性的灵活动态语言, Groovy保证了这些特性像 Java语法一样被 Java开发者使用。
除了语言和Java相通外,Groovy有时候又像一种脚本语言。前文也提到过,当我执行Groovy脚本时,Groovy会先将其编译成Java类字节码,然后通过Jvm来执行这个Java类。图1展示了Java、Groovy和Jvm之间的关系。
|
图1 Java、Groovy和JVM的关系 |
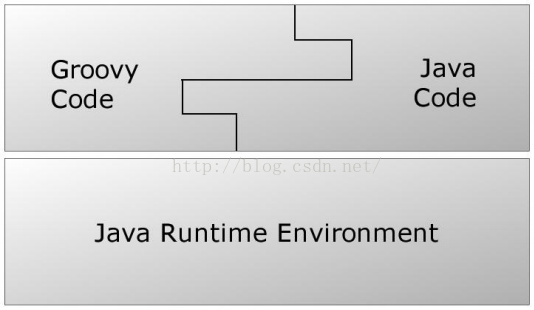
实际上,由于Groovy Code在真正执行的时候已经变成了Java字节码,所以JVM根本不知道自己运行的是Groovy代码。
下面我们将介绍Groovy。由于此文的主要目的是Gradle,所以我们不会过多讨论Groovy中细枝末节的东西,而是把知识点集中在以后和Gradle打交道时一些常用的地方上。
3.1 Groovy开发环境
在学习本节的时候,最好部署一下Groovy开发环境。根据Groovy官网的介绍(http://www.groovy-lang.org/download.html#gvm),部署Groovy开发环境非常简单,在Ubuntu或者cygwin之类的地方:
- curl -s get.gvmtool.net | bash
- source"$HOME/.gvm/bin/gvm-init.sh"
- gvm install groovy
执行完最后一步,Groovy就下载并安装了。图1是安装时候的示意图
|
图1 Groovy安装示意图 |
然后,创建一个test.groovy文件,里边只有一行代码:
println "hello groovy"
执行groovy test.groovy,输出结果如图2所示:
|
图2 执行groovy脚本 |

亲们,必须要完成上面的操作啊。做完后,有什么感觉和体会?
最大的感觉可能就是groovy和shell脚本,或者python好类似。
另外,除了可以直接使用JDK之外,Groovy还有一套GDK,网址是http://www.groovy-lang.org/api.html。
说实话,看了这么多家API文档,还是Google的Android API文档做得好。其页面中右上角有一个搜索栏,在里边输入一些关键字,瞬间就能列出候选类,相关文档,方便得不得了啊.....
3.2 一些前提知识
为了后面讲述方面,这里先介绍一些前提知识。初期接触可能有些别扭,看习惯就好了。
l Groovy注释标记和Java一样,支持//或者/**/
l Groovy语句可以不用分号结尾。Groovy为了尽量减少代码的输入,确实煞费苦心
l Groovy中支持动态类型,即定义变量的时候可以不指定其类型。Groovy中,变量定义可以使用关键字def。注意,虽然def不是必须的,但是为了代码清晰,建议还是使用def关键字
def variable1 = 1 //可以不使用分号结尾
def varable2 = "I ama person"
def int x = 1 //变量定义时,也可以直接指定类型
l 函数定义时,参数的类型也可以不指定。比如
String testFunction(arg1,arg2){//无需指定参数类型
...
}
l 除了变量定义可以不指定类型外,Groovy中函数的返回值也可以是无类型的。比如:
//无类型的函数定义,必须使用def关键字
def nonReturnTypeFunc(){
last_line //最后一行代码的执行结果就是本函数的返回值
}
//如果指定了函数返回类型,则可不必加def关键字来定义函数
String getString(){
return"I am a string"
}
其实,所谓的无返回类型的函数,我估计内部都是按返回Object类型来处理的。毕竟,Groovy是基于Java的,而且最终会转成Java Code运行在JVM上
l 函数返回值:Groovy的函数里,可以不使用returnxxx来设置xxx为函数返回值。如果不使用return语句的话,则函数里最后一句代码的执行结果被设置成返回值。比如
//下面这个函数的返回值是字符串"getSomething return value"
def getSomething(){
"getSomething return value" //如果这是最后一行代码,则返回类型为String
1000//如果这是最后一行代码,则返回类型为Integer
}
注意,如果函数定义时候指明了返回值类型的话,函数中则必须返回正确的数据类型,否则运行时报错。如果使用了动态类型的话,你就可以返回任何类型了。
l Groovy对字符串支持相当强大,充分吸收了一些脚本语言的优点:
1 单引号''中的内容严格对应Java中的String,不对$符号进行转义
defsingleQuote='I am $ dolloar' //输出就是I am $ dolloar
2 双引号""的内容则和脚本语言的处理有点像,如果字符中有$号的话,则它会$表达式先求值。
defdoubleQuoteWithoutDollar = "I am one dollar" //输出 I am one dollar
def x = 1
defdoubleQuoteWithDollar = "I am $x dolloar" //输出I am 1 dolloar
3 三个引号'''xxx'''中的字符串支持随意换行 比如
defmultieLines = ''' begin
line 1
line 2
end '''
l 最后,除了每行代码不用加分号外,Groovy中函数调用的时候还可以不加括号。比如:
println("test") ---> println"test"
注意,虽然写代码的时候,对于函数调用可以不带括号,但是Groovy经常把属性和函数调用混淆。比如
def getSomething(){
"hello"
}
getSomething() //如果不加括号的话,Groovy会误认为getSomething是一个变量。比如:
|
图3 错误示意 |

所以,调用函数要不要带括号,我个人意见是如果这个函数是Groovy API或者Gradle API中比较常用的,比如println,就可以不带括号。否则还是带括号。Groovy自己也没有太好的办法解决这个问题,只能兵来将挡水来土掩了。
好了,了解上面一些基础知识后,我们再介绍点深入的内容。
3.3 Groovy中的数据类型
Groovy中的数据类型我们就介绍两种和Java不太一样的:
- 一个是Java中的基本数据类型。
- 另外一个是Groovy中的容器类。
- 最后一个非常重要的是闭包。
放心,这里介绍的东西都很简单
3.3.1 基本数据类型
作为动态语言,Groovy世界中的所有事物都是对象。所以,int,boolean这些Java中的基本数据类型,在Groovy代码中其实对应的是它们的包装数据类型。比如int对应为Integer,boolean对应为Boolean。比如下图中的代码执行结果:
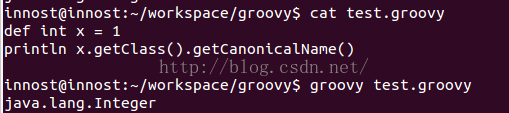
图4 int实际上是Integer
3.3.2 容器类
Groovy中的容器类很简单,就三种:
- l List:链表,其底层对应Java中的List接口,一般用ArrayList作为真正的实现类。
- l Map:键-值表,其底层对应Java中的LinkedHashMap。
- l Range:范围,它其实是List的一种拓展。
对容器而言,我们最重要的是了解它们的用法。下面是一些简单的例子:
1. List类
变量定义:List变量由[]定义,比如 def aList = [5,'string',true] //List由[]定义,其元素可以是任何对象 变量存取:可以直接通过索引存取,而且不用担心索引越界。如果索引超过当前链表长度,List会自动 往该索引添加元素 assert aList[1] == 'string' assert aList[5] == null //第6个元素为空 aList[100] = 100 //设置第101个元素的值为10 assert aList[100] == 100 那么,aList到现在为止有多少个元素呢? println aList.size ===>结果是101
2. Map类
容器变量定义 变量定义:Map变量由[:]定义,比如 def aMap = ['key1':'value1','key2':true] Map由[:]定义,注意其中的冒号。冒号左边是key,右边是Value。key必须是字符串,value可以是任何对象。另外,key可以用''或""包起来,也可以不用引号包起来。比如 def aNewMap = [key1:"value",key2:true]//其中的key1和key2默认被 处理成字符串"key1"和"key2" 不过Key要是不使用引号包起来的话,也会带来一定混淆,比如 def key1="wowo" def aConfusedMap=[key1:"who am i?"] aConfuseMap中的key1到底是"key1"还是变量key1的值“wowo”?显然,答案是字符串"key1"。如果要是"wowo"的话,则aConfusedMap的定义必须设置成: def aConfusedMap=[(key1):"who am i?"] Map中元素的存取更加方便,它支持多种方法: println aMap.keyName <==这种表达方法好像key就是aMap的一个成员变量一样 println aMap['keyName'] <==这种表达方法更传统一点 aMap.anotherkey = "i am map" <==为map添加新元素
3. Range类
Range是Groovy对List的一种拓展,变量定义和大体的使用方法如下:
def aRange = 1..5 <==Range类型的变量 由begin值+两个点+end值表示
左边这个aRange包含1,2,3,4,5这5个值
如果不想包含最后一个元素,则
def aRangeWithoutEnd = 1..<5 <==包含1,2,3,4这4个元素
println aRange.from
println aRange.to
3.3.4 Groovy API的一些秘笈
前面讲这些东西,主要是让大家了解Groovy的语法。实际上在coding的时候,是离不开SDK的。由于Groovy是动态语言,所以要使用它的SDK也需要掌握一些小诀窍。
Groovy的API文档位于http://www.groovy-lang.org/api.html
以上文介绍的Range为例,我们该如何更好得使用它呢?
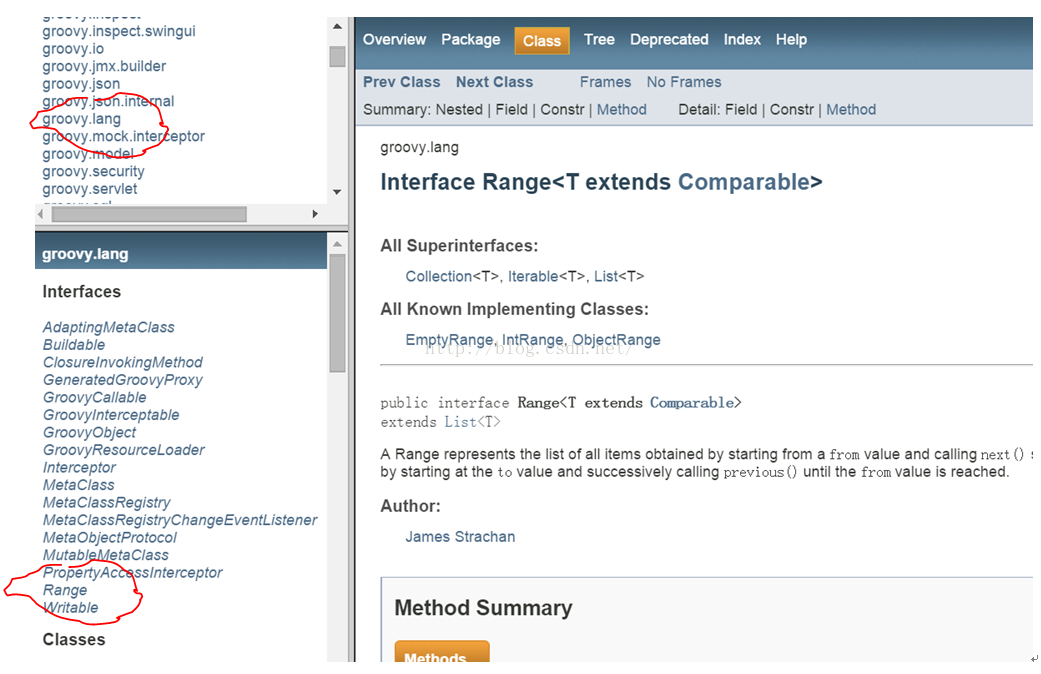
l 先定位到Range类。它位于groovy.lang包中:
|
图5 Range类API文档 |
有了API文档,你就可以放心调用其中的函数了。不过,不过,不过:我们刚才代码中用到了Range.from/to属性值,但翻看Range API文档的时候,其实并没有这两个成员变量。图6是Range的方法
|
图6 Range类的方法 |
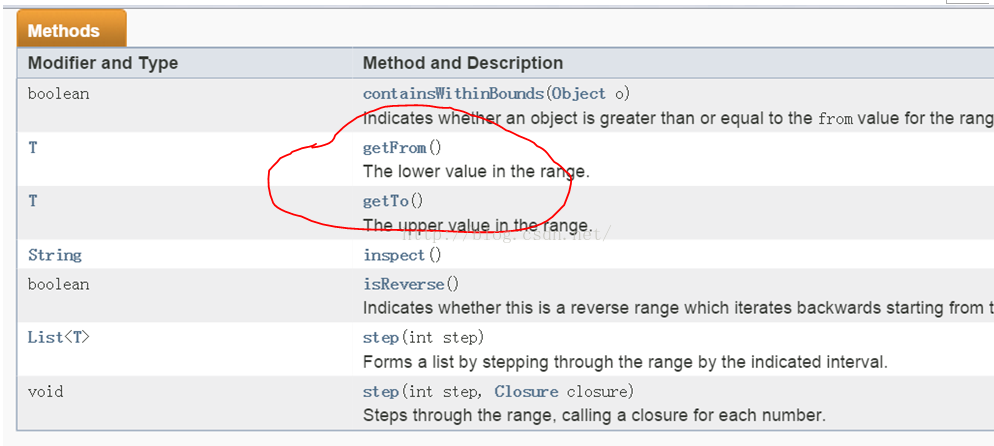
文档中并没有说明Range有from和to这两个属性,但是却有getFrom和getTo这两个函数。What happened?原来:
根据Groovy的原则,如果一个类中有名为xxyyzz这样的属性(其实就是成员变量),Groovy会自动为它添加getXxyyzz和setXxyyzz两个函数,用于获取和设置xxyyzz属性值。
注意,get和set后第一个字母是大写的
所以,当你看到Range中有getFrom和getTo这两个函数时候,就得知道潜规则下,Range有from和to这两个属性。当然,由于它们不可以被外界设置,所以没有公开setFrom和setTo函数。
3.4 闭包
3.4.1 闭包的样子
闭包,英文叫Closure,是Groovy中非常重要的一个数据类型或者说一种概念了。闭包的历史来源,种种好处我就不说了。我们直接看怎么使用它!
闭包,是一种数据类型,它代表了一段可执行的代码。其外形如下: co
def aClosure = {//闭包是一段代码,所以需要用花括号括起来..
Stringparam1, int param2 -> //这个箭头很关键。箭头前面是参数定义,箭头后面是代码
println"this is code" //这是代码,最后一句是返回值,
//也可以使用return,和Groovy中普通函数一样
}
简而言之,Closure的定义格式是:r><br>
<pre name="code" class="java">def xxx = {paramters -> code} //或者
def xxx = {无参数,纯code} 这种case不需要->符号</pre><b
说实话,从C/C++语言的角度看,闭包和函数指针很像。闭包定义好后,要调用它的方法就是:
闭包对象.call(参数) 或者更像函数指针调用的方法:
闭包对象(参数)
比如:
aClosure.call("this is string",100) 或者
aClosure("this is string", 100
上面就是一个闭包的定义和使用。在闭包中,还需要注意一点:
如果闭包没定义参数的话,则隐含有一个参数,这个参数名字叫it,和this的作用类似。it代表闭包的参数。
比如:
def greeting = { "Hello, $it!" }
assert greeting('Patrick') == 'Hello, Patrick!'
等同于:
def greeting = { it -> "Hello, $it!"}
assert greeting('Patrick') == 'Hello, Patrick!'
但是,如果在闭包定义时,采用下面这种写法,则表示闭包没有参数!
def noParamClosure = { -> true }
这个时候,我们就不能给noParamClosure传参数了!
noParamClosure ("test") <==报错喔!
3.4.2 Closure使用中的注意点
1. 省略圆括号
闭包在Groovy中大量使用,比如很多类都定义了一些函数,这些函数最后一个参数都是一个闭包。比如:
public static <T> List<T>each(List<T> self, Closure closure)
上面这个函数表示针对List的每一个元素都会调用closure做一些处理。这里的closure,就有点回调函数的感觉。但是,在使用这个each函数的时候,我们传递一个怎样的Closure进去呢?比如:
def iamList = [1,2,3,4,5] //定义一个List
iamList.each{ //调用它的each,这段代码的格式看不懂了吧?each是个函数,圆括号去哪了?
println it
}
上面代码有两个知识点:
l each函数调用的圆括号不见了!原来,Groovy中,当函数的最后一个参数是闭包的话,可以省略圆括号。比如
def testClosure(int a1,String b1, Closure closure){
//dosomething
closure() //调用闭包
}
那么调用的时候,就可以免括号!
testClosure (4, "test", {
println"i am in closure"
} ) //红色的括号可以不写..
注意,这个特点非常关键,因为以后在Gradle中经常会出现图7这样的代码:
|
图7 闭包调用 |
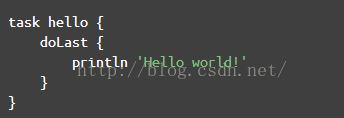
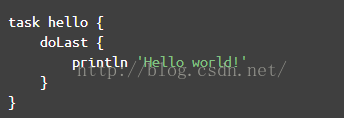
经常碰见图7这样的没有圆括号的代码。省略圆括号虽然使得代码简洁,看起来更像脚本语言,但是它这经常会让我confuse(不知道其他人是否有同感),以doLast为例,完整的代码应该按下面这种写法:
doLast({
println'Hello world!'
})
有了圆括号,你会知道 doLast只是把一个Closure对象传了进去。很明显,它不代表这段脚本解析到doLast的时候就会调用println "Hello world!" 。
但是把圆括号去掉后,就感觉好像println "Hello world!"立即就会被调用一样!
2. 如何确定Closure的参数
另外一个比较让人头疼的地方是,Closure的参数该怎么搞?还是刚才的each函数:
public static <T> List<T> each(List<T>self, Closure closure)
如何使用它呢?比如:
def iamList = [1,2,3,4,5] //定义一个List变量
iamList.each{ //调用它的each函数,只要传入一个Closure就可以了。
println it
}
看起来很轻松,其实:
l 对于each所需要的Closure,它的参数是什么?有多少个参数?返回值是什么?
我们能写成下面这样吗?
[java] view plain copy
iamList.each{String name,int x ->
return x
} //运行的时候肯定报错! 所以,Closure虽然很方便,但是它一定会和使用它的上下文有极强的关联。要不,作为类似回调这样的东西,我如何知道调用者传递什么参数给Closure呢?
此问题如何破解?只能通过查询API文档才能了解上下文语义。比如下图8:
|
图8 文档说明 |
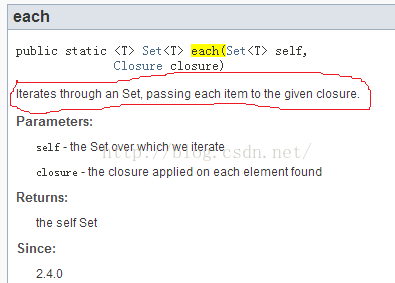
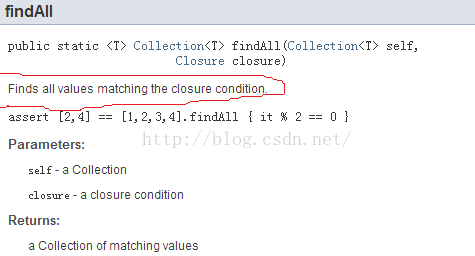
图8中:
- each函数说明中,将给指定的closure传递Set中的每一个item。所以,closure的参数只有一个。
- findAll中,绝对抓瞎了。一个是没说明往Closure里传什么。另外没说明Closure的返回值是什么.....。
对Map的findAll而言,Closure可以有两个参数。findAll会将Key和Value分别传进去。并且,Closure返回true,表示该元素是自己想要的。返回false表示该元素不是自己要找的。示意代码如图9所示:
|
图9 Closure调用示例 |
Closure的使用有点坑,很大程度上依赖于你对API的熟悉程度,所以最初阶段,SDK查询是少不了的。
3.5 脚本类、文件I/O和XML操作
最后,我们来看一下Groovy中比较高级的用法。
3.5.1 脚本类
1. 脚本中import其他类
Groovy中可以像Java那样写package,然后写类。比如在文件夹com/cmbc/groovy/目录中放一个文件,叫Test.groovy,如图10所示:
|
图10 com/cmbc/groovy/Test.groovy文件 |
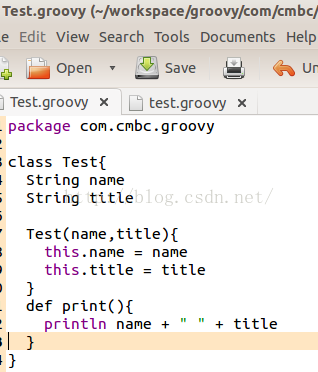
你看,图10中的Test.groovy和Java类就很相似了。当然,如果不声明public/private等访问权限的话,Groovy中类及其变量默认都是public的。
现在,我们在测试的根目录下建立一个test.groovy文件。其代码如下所示:
|
图11 test.groovy访问com/cmbc/groovy包 |
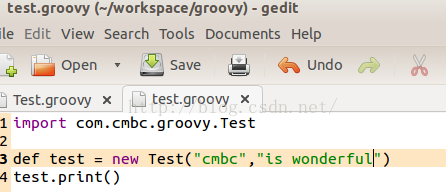
你看,test.groovy先import了com.cmbc.groovy.Test类,然后创建了一个Test类型的对象,接着调用它的print函数。
这两个groovy文件的目录结构如图12所示:
|
图12 Test.groovy和test.groovy目录结构 |
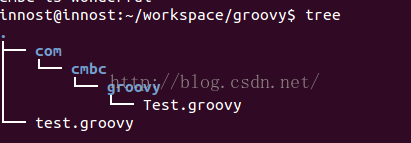
在groovy中,系统自带会加载当前目录/子目录下的xxx.groovy文件。所以,当执行groovy test.groovy的时候,test.groovy import的Test类能被自动搜索并加载到。
2. 脚本到底是什么
Java中,我们最熟悉的是类。但是我们在Java的一个源码文件中,不能不写class(interface或者其他....),而Groovy可以像写脚本一样,把要做的事情都写在xxx.groovy中,而且可以通过groovy xxx.groovy直接执行这个脚本。这到底是怎么搞的?
既然是基于Java的,Groovy会先把xxx.groovy中的内容转换成一个Java类。比如:
test.groovy的代码是:
println 'Groovy world!'
Groovy把它转换成这样的Java类:
执行 groovyc-d classes test.groovy
groovyc是groovy的编译命令,-dclasses用于将编译得到的class文件拷贝到classes文件夹下
图13是test.groovy脚本转换得到的java class。用jd-gui反编译它的代码:
|
图13 groovy脚本反编译得到的Java类源码 |
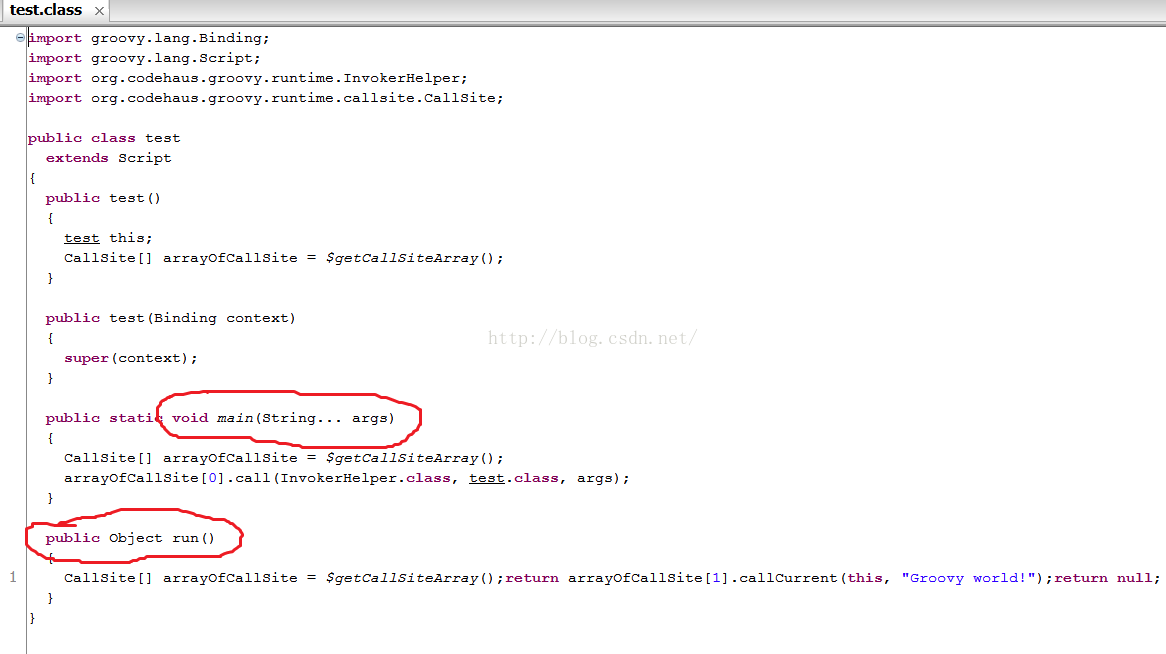
图13中:
- test.groovy被转换成了一个test类,它从script派生。
- 每一个脚本都会生成一个static main函数。这样,当我们groovytest.groovy的时候,其实就是用java去执行这个main函数
- 脚本中的所有代码都会放到run函数中。比如,println "Groovy world",这句代码实际上是包含在run函数里的。
- 如果脚本中定义了函数,则函数会被定义在test类中。
groovyc是一个比较好的命令,读者要掌握它的用法。然后利用jd-gui来查看对应class的Java源码。
3. 脚本中的变量和作用域
前面说了,xxx.groovy只要不是和Java那样的class,那么它就是一个脚本。而且脚本的代码其实都会被放到run函数中去执行。那么,在Groovy的脚本中,很重要的一点就是脚本中定义的变量和它的作用域。举例:
def x = 1 <==注意,这个x有def(或者指明类型,比如 int x = 1)
def printx(){
println x
}
printx() <==报错,说x找不到
为什么?继续来看反编译后的class文件。
|
图14 反编译后的test.class文件 |
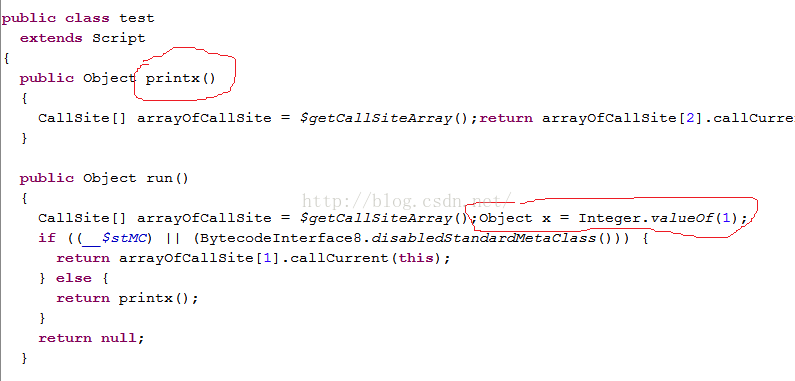
图14中:
l printx被定义成test类的成员函数
l def x = 1,这句话是在run中创建的。所以,x=1从代码上看好像是在整个脚本中定义的,但实际上printx访问不了它。printx是test成员函数,除非x也被定义成test的成员函数,否则printx不能访问它。
那么,如何使得printx能访问x呢?很简单,定义的时候不要加类型和def。即:
x = 1 <==注意,去掉def或者类型
def printx(){
println x
}
printx() <==OK
这次Java源码又变成什么样了呢?
|
图15 进化版的test.groovy |
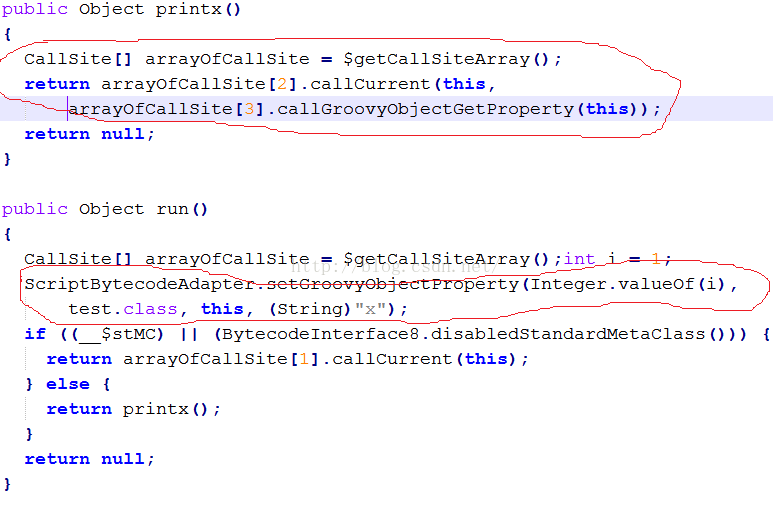
图15中,x也没有被定义成test的成员函数,而是在run的执行过程中,将x作为一个属性添加到test实例对象中了。然后在printx中,先获取这个属性。
注意,Groovy的文档说 x = 1这种定义将使得x变成test的成员
- 上一篇:没有了
- 下一篇:没有了
