
GIS+=地理信息+行业+大数据——Spark集群下SPARK SQL开发测试介绍
Spark集群下SPARK SQL开发介绍
在之前的文章《SPARK for IntelliJ IDEA 开发环境部署》中已经完成了对开发环境的搭建工作,下面就可以开发程序了。对于GIS的数据分析需要通过SQL查询和空间查询来实现对空间数据的查询和检索。而Spark SQL是进行属性查询的主要工具,下面就利用Spark SQL技术针对自己组织的数据进行SQL查询的功能开发。
开发环境
操作系统:Ubuntu 14
开发工具:IntelliJ IDEA 15
开发语言:scala 2.10.6
Java版本:JDK 1.7
开发的功能主要是模拟一个json数据文件,在集群环境下读取该数据,并对其数据进行sql查询。下面开始开发,创建一个scala类文件命名为mysqltest,代码如下:
01.import org.apache.spark.sql.SQLContext
02.import org.apache.spark.{SparkContext, SparkConf}
03.import scala.sys.SystemProperties
04.
05.object mysqltest {
06.def main(args: Array[String]) {
07.val sparkConf=new SparkConf().setAppName("mysqltest")
08.sparkConf.setMaster("spark://192.168.12.154:7077")
09.val sc=new SparkContext(sparkConf)
10.sc.addJar("/home/test.jar")
11.val sqlContext = new SQLContext(sc)
12.val dd=new SystemProperties()
13.val sparkhome=dd.get("SPARK_HOME")
14.val _ar=args
15.val sss=sys.props
16.val sparkhomepath="/home/sougou.json"
17.val sougou = sqlContext.read.json(sparkhomepath)
18.// 输出schema结构
19.sougou.printSchema()
20.// 注册DataFrame 为一个table.
21.sougou.registerTempTable("sougou")
22.// 通过sqlContext对象进行SQL查询
23.var arry=sqlContext.sql("SELECT * FROM sougou WHERE num >= 13 AND num <= 100")
24.//show方法默认显示20条记录的结果记录
25.arry.show()
26.sc.stop()
27.}
28.}
注:在开发调试状态下需要添加setMaster和addJar方法
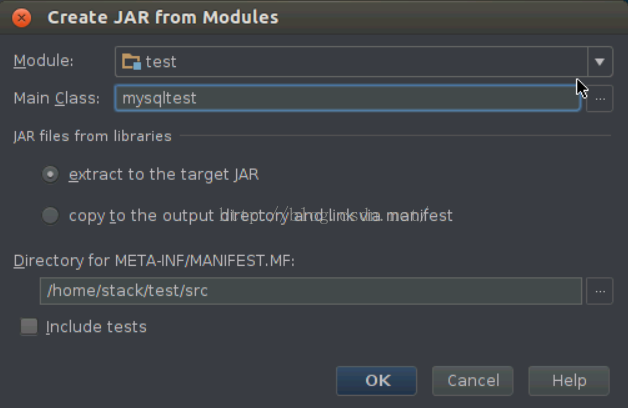
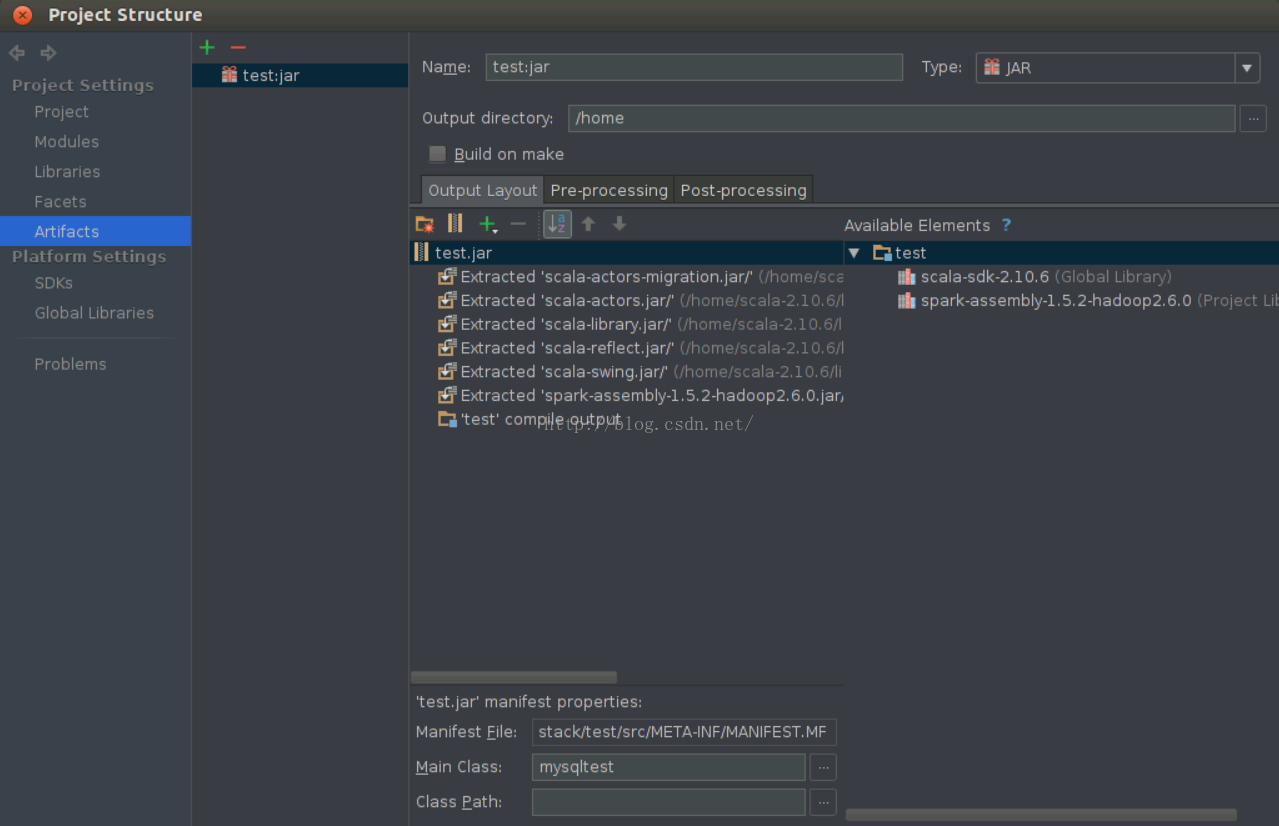
为了测试程序在Spark集群环境下的分布式计算的效果,需要把程序打成jar包,才能运行在spark 集群中,可以按照以下步骤操作:依次选择“File”–> “Project Structure” –> “Artifact”,选择“+”–> “Jar” –> “From Modules with dependencies”,选择main函数,并在弹出框中选择输出jar位置,并选择“OK”。
声明:该文观点仅代表作者本人,入门客AI创业平台信息发布平台仅提供信息存储空间服务,如有疑问请联系rumenke@qq.com。
- 上一篇:没有了
- 下一篇:没有了

copyright © 2008-2019 入门客AI创业平台 版权所有 备案号:湘ICP备2023012770号