
UNICODE 转 UTF8
确切的说这里的UNICODE编码指的是UCS2编码,我们开发Windows应用程序所用wchar_t 类型数组所保存的字符应该是UCS2编码的,这很容易让人误以为UNICODE是两个字节编码的。其实UNICODE 代表的是一种字符集,也就是字符编码方案,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何在计算机上存储,而UTF8,UTF16,UCS2这些编码方式则是UNICODE的各种实现方式,规定了UNICODE二进制代码在计算机的表示方式。另外UCS2编码并不能完全表示UNICODE字符集。
从UCS2到UTF-8编码方式如下:
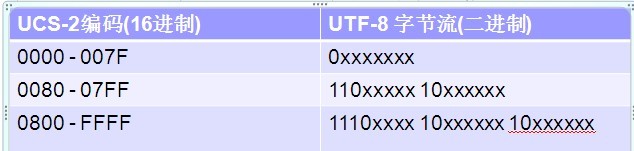
/*
参数:
strUnicode : Unicode字符串指针
strUnicodeLen : Unicode字符串长度
strUTF8 : UTF8字符串指针
strUTF8Len : UTF8字符串字节数,如需取得转换所需字节数,可向该值传入-1.
返回值 : 转换后所得UTF8字符串字节数, -1 表示转换失败
*/
int UnicodeToUTF_8(wchar_t *strUnicode, int strUnicodeLen, char *strUTF8, int strUTF8Len)
{
if((strUnicode == NULL) || (strUnicodeLen <= 0) || (strUTF8Len <= 0 && strUTF8Len != -1))
{
return -1;
}
int i, offset = 0;
if(strUTF8Len == -1)
{
for(i = 0; i < strUnicodeLen; i++)
{
if(strUnicode[i] <= 0x007f) //单字节编码
{
offset += 1;
}
else if(strUnicode[i] >= 0x0080 && strUnicode[i] <= 0x07ff) //双字节编码
{
offset += 2;
}
else if(strUnicode[i] >= 0x0800 && strUnicode[i] <= 0xffff) //三字节编码
{
offset += 3;
}
}
return offset + 1;
}
else
{
if(strUTF8 == NULL)
{
return -1;
}
for(i = 0; i < strUnicodeLen; i++)
{
if(strUnicode[i] <= 0x007f) //单字节编码
{
strUTF8[offset++] = (char)(strUnicode[i] & 0x007f);
}
else if(strUnicode[i] >= 0x0080 && strUnicode[i] <= 0x07ff) //双字节编码
{
strUTF8[offset++] = (char)(((strUnicode[i] & 0x07c0) >> 6) | 0x00c0);
strUTF8[offset++] = (char)((strUnicode[i] & 0x003f) | 0x0080);
}
else if(strUnicode[i] >= 0x0800 && strUnicode[i] <= 0xffff) //三字节编码
{
strUTF8[offset++] = (char)(((strUnicode[i] & 0xf000) >> 12) | 0x00e0);
strUTF8[offset++] = (char)(((strUnicode[i] & 0x0fc0) >> 6) | 0x0080);
strUTF8[offset++] = (char)((strUnicode[i] & 0x003f) | 0x0080);
}
}
strUTF8[offset] = "�";
return offset + 1;
}
}声明:该文观点仅代表作者本人,入门客AI创业平台信息发布平台仅提供信息存储空间服务,如有疑问请联系rumenke@qq.com。
- 上一篇:没有了
- 下一篇:没有了
