入门客AI创业平台
(我带你入门,你带我飞行)
课程搜索
老师搜索
文章搜索
手册搜索
手册文章
搜索
入门客AI创业平台首页
学习手册
在线课程
博文笔记
博客笔记
当前位置:
入门客AI创业平台
>
博文笔记
10
2016-05
【
】
查找算法(顺序查找、二分法查找、二叉树查找、hash查找)
2016-05-10
http://student.zjzk.cn/course_ware/data_structure/web/chazhao/chazhao9.3.1.5.htm 查找功能是数据处理的一个基本功能。数据查找并不复杂,但是如何实现数据又快
【
】
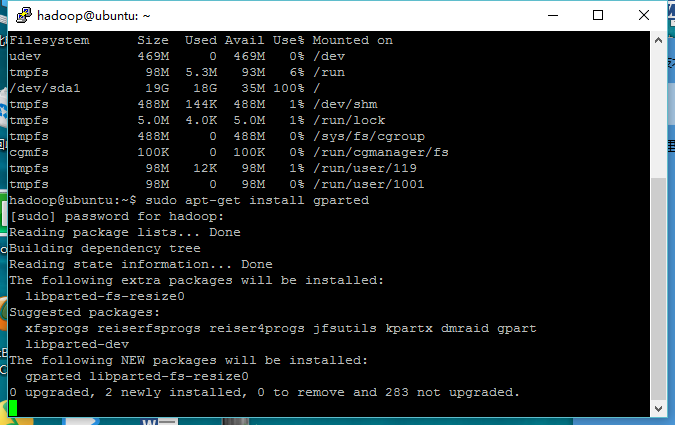
解决hadoop伪分布式下hdfs存储空间不足的问题
2016-05-23
运行环境:虚拟机下Ubuntu15.0 问题的产生:在运行hadoop fs -put的指令时把一个大型文件从本地复制到hdfs时,运行到一半突然复制中断,报“name node is in safe mode
08
2008-10
【
】
二分法查找
2008-10-08
二分法查找 1、二分查找(Binary Search) 二分查找又称折半查找,它是一种效率较高的查找方法。 二分查找要求:线性表是有序表,即
06
2017-09
【
】
kylin使用中曾遇到的问题整理
2017-09-06
1.1. kylin安装问题 1.1.1. 问题1:Please make sure the user has the privilege to run hive shell [root@localhost65 apache-kylin-1.6.0-bin]# [root@localhost65 apache-kylin-1.6.0-bin]#
【
】
Kylin单机集成CDH
2018-01-08
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力(可以把Kylin定义为OLAP on Hadoop)。Apache Kylin于2015年11
06
2017-09
【
】
kylin安装及配置
2017-09-06
1.1. KYLIN安装 1.1.1. 安装环境 安装环境: jdk-8u65-linux-x64.tar.gz hadoop-2.6.2.tar.gz hadoop-native-64-2.6.0.tar zookeeper-3.4.6.tar.gz hbase-1.1.5-bin.tar.gz apache-hive-2.1.1
【
】
Hadoop的JVM重用
2017-08-05
Hadoop的JVM重用 hadoopjvm参数配置 Hadoop中有个参数是mapred.job.reuse.jvm.num.tasks,默认是1,表示一个JVM上最多可以顺序执行的task数目(属于同一个Job
18
2017-12
【
】
mongodb重启问题
2017-12-18
1、错误的做法 mongodb重启时,经常遇到 child process failed, exited with error number 1和 child process failed, exited with error number 100的问题,之前我是通过删除mongodb的数据
【
】
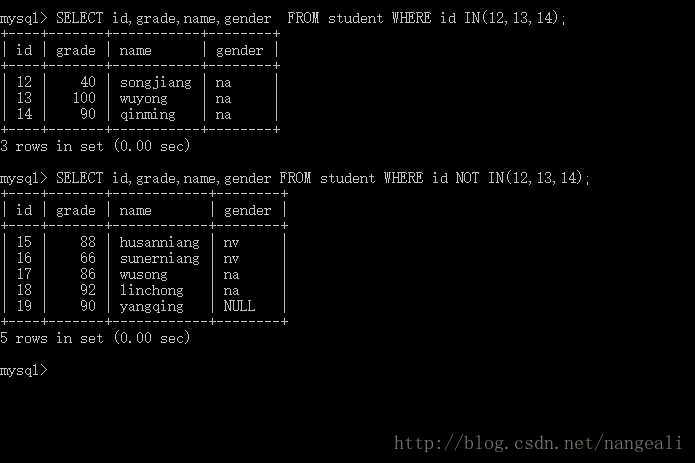
MySQL带IN关键字的查询
2017-07-01
IN关键字,用于判断某个记录的值,是否在指定的集合中 如果字段的值在集合中,则满足条件,该字段所在的记录将会被查询出来。 SELECT * | 字段名1,字段
24
2017-02
【
】
linux下自动检测mongodb 有问题就重启
2017-02-24
import os import time import datetime output = os.popen("service mongod status").read() print( time.strftime( "%Y-%m-%d %H:%M:%S", time.localtime( time.time() ) ) ) print( output ) if "locked" in
首页
上一页
1868
1869
1870
1871
1872
1873
1874
1875
1876
1877
下一页
末页
热门文章
php大讲堂系列1《什么是php》
PHP 面向对象
「论坛技术求助区-精华帖」DIV+CSS...
php应用:平台搭建PHP开发环境:PHP...
sql中HAVING的使用说明
JAVA java Java基础编程之多态与继承...
Java入门教程系列「1」Java基本数据...
Java知识点总结之第一个Java程序
新手看Java,Java的基本特点
自己几分钟动手搭建一个简易的Spr...
最新文章
剑指 Offer - 8:跳台阶
Netty权威指南_札记02_NIO编程
mysql时间属性之时间戳和datetime之...
虚拟现实或许可以拯救古埃及的“...
spring cloud服务注册中心eureka---集群...
Java SE 第六章
HTTP请求+数据库
HIDL学习笔记之HIDL C++(第二天)
ubuntu系统下指定tomcat运行时为JDK1.8...
Play Framework Web开发教程 16 处理HTT...
copyright © 2008-2019 入门客AI创业平台 版权所有 备案号:
湘ICP备2023012770号