mysql> select * from abc_number_prop where number_id in (select number_id from abc_number_phone where phone = "82306839");
为了节省篇幅,省略了输出内容,下同。
67 rows in set (1
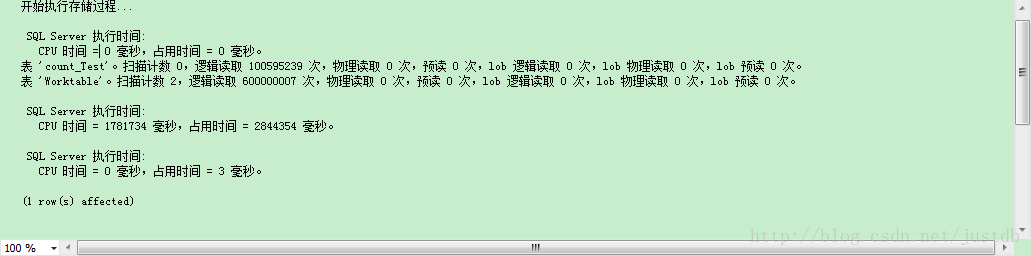
开发说他写了个SQL特别慢,让看看。
select * from t_channel where id_ in(select distinct cdbh from sjkk_gcjl where jgsj>"2015-01-02 08:00:00" and jgsj select distinct cdbh from sjkk_