入门客AI创业平台
(我带你入门,你带我飞行)
课程搜索
老师搜索
文章搜索
手册搜索
手册文章
搜索
入门客AI创业平台首页
学习手册
在线课程
博文笔记
博客笔记
当前位置:
入门客AI创业平台
>
博文笔记
【
】
【Linux】C语言实现文件夹拷贝
2015-12-25
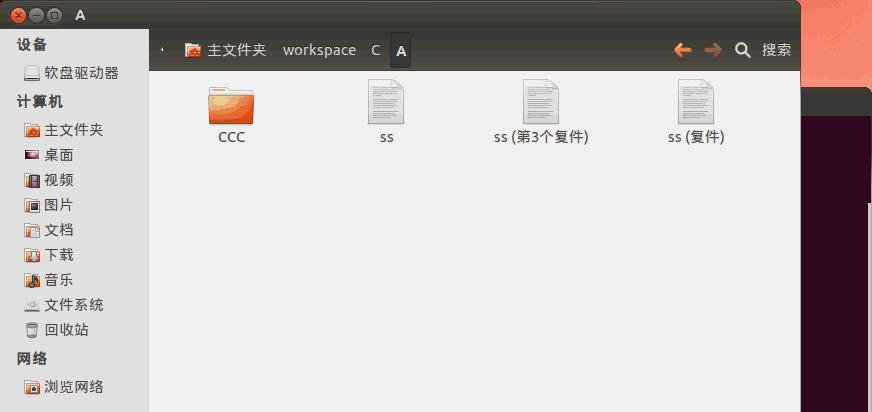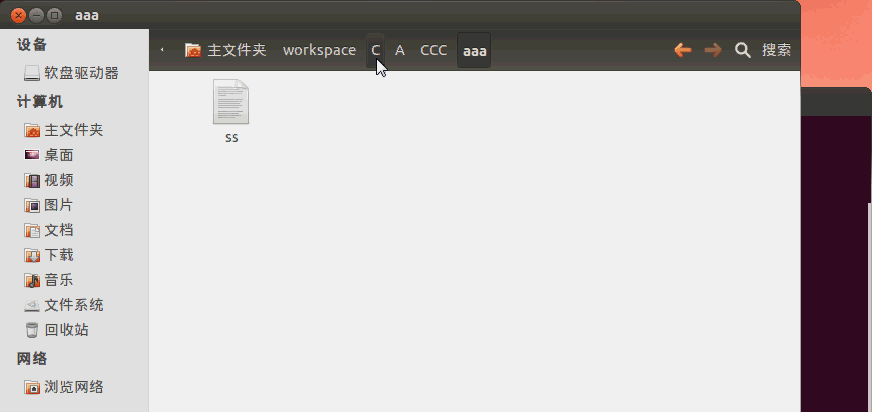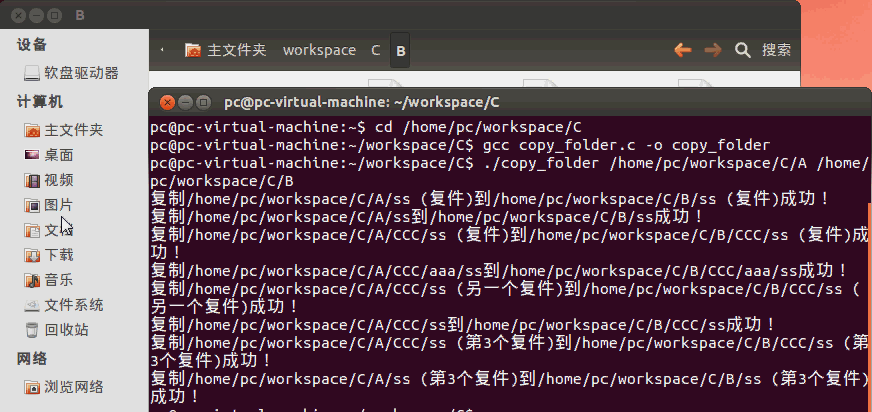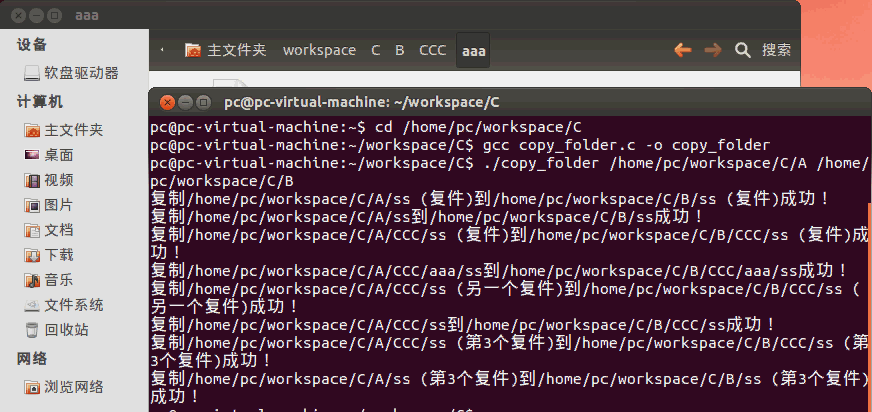
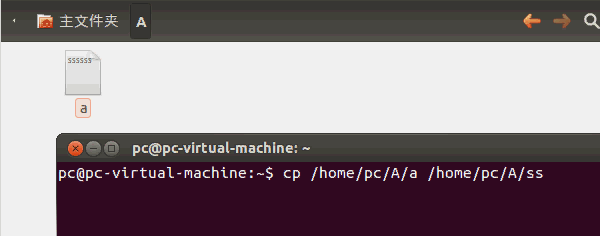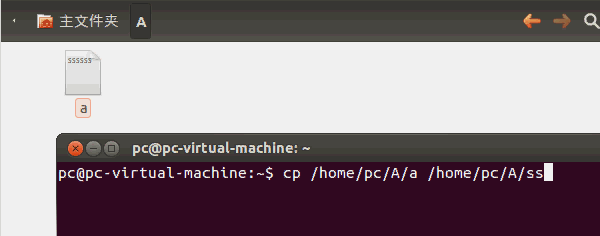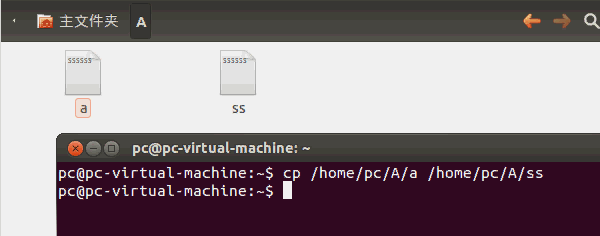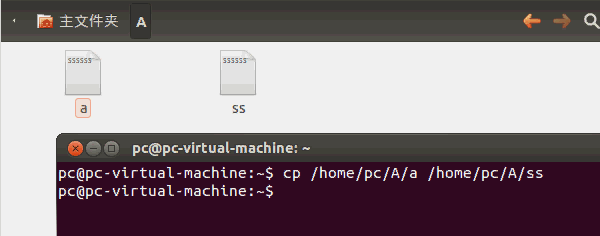
在《【Linux】利用C语言文件流复制单一文件》(点击打开链接)讲述了如何用C语言拷贝文件,但是这只能拷贝单一文件。如果你要用LinuxC拷贝整个
07
2016-12
【
】
Linux下的几种文件拷贝方式效率对比
2016-12-07
不管是哪种操作系统,要实现文件拷贝,必须陷入内核,从磁盘读取文件内容,然后存储到另一个文件。实现文件拷贝最通常的做法是:读取文件用
15
2015-07
【
】
Linux C 实现mycp 可以显示文件拷贝进度
2015-07-15
在Linux系统里面用到 cp命令复制不能显示文件拷贝的进度,也不能计算还有多长时间文件可以 拷贝结束,现在写一个程序可以显示文件拷贝的进度。 思路:当
17
2017-04
【
】
Linux C编程之IO-文件拷贝
2017-04-17
1.1文件拷贝 本次文件拷贝需要使用到如下三个函数原型: 打开文件 FILE * fopen(const char * path,const char * mode); 相关函数:open,fclose,fopen_s,_wfopen 返回值
【
】
【Linux】利用C语言文件流复制单一文件
2015-12-19
LinuxC下的复制单一文件与其它语言的没有区别,对于文件操作皆要用到文件流、文件流的缓冲区的概念,可能这就是操作系统中的共性吧!网上对于
01
2017-04
【
】
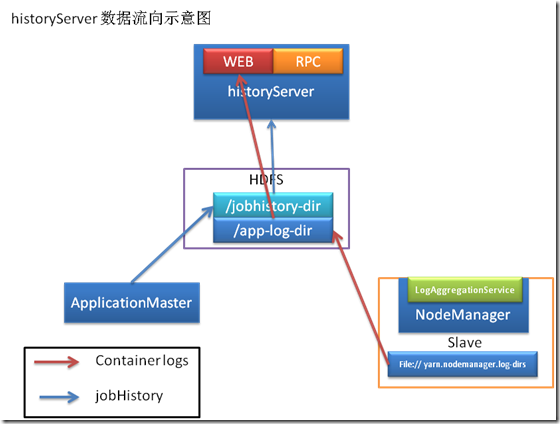
Hadoop学习笔记9@JobHistoryServer详解
2017-04-01
历史服务器,管理者可以通过历史服务器查看已经运行完成的Mapreduce作业记录,比如用了多少个Map、多少个Reduce、作业提交时间、作业
【
】
hadoop2.x配置 - HistoryServer原理详解
2014-06-12
refer:http://www.cnblogs.com/shenh062326/archive/2012/12/16/2820381.html -----------------------------------------------------------------------------------------------------------------------
31
2013-01
【
】
yarn historyserver 使用解析
2013-01-31
启动服务: sbin/mr-jobhistory-daemon.sh start historyserver 查询历史页面: http://202.117.10.25:19888/jobhistory 1. job完成后,历史信息存入hdfs下的mr-history/done/中
【
】
Hadoop的jobhistoryserver配置
2017-01-19
简介 本文介绍hadoop的jobhistoryserver如何进行配置.在MRv2中我们要出查看job的log信息,需要启动jobhistory服务. 配置 jobhistory的配置信息在$HADOOP_HOME/etc/hadoop/mapred
【
】
hadoop yarn jobhistoryserver 配置
2016-09-08
hadoop1.x之前的版本中可以开启50030端口,查看历史作业的运行日志,包括mr日志和自定义日志,但是hadoop2.x 是用MRv2(yarn)作为作业运行服务,代替50030端口的
首页
上一页
2536
2537
2538
2539
2540
2541
2542
2543
2544
2545
下一页
末页
热门文章
php大讲堂系列1《什么是php》
PHP 面向对象
「论坛技术求助区-精华帖」DIV+CSS...
php应用:平台搭建PHP开发环境:PHP...
sql中HAVING的使用说明
JAVA java Java基础编程之多态与继承...
Java入门教程系列「1」Java基本数据...
Java知识点总结之第一个Java程序
新手看Java,Java的基本特点
自己几分钟动手搭建一个简易的Spr...
最新文章
剑指 Offer - 8:跳台阶
Netty权威指南_札记02_NIO编程
mysql时间属性之时间戳和datetime之...
虚拟现实或许可以拯救古埃及的“...
spring cloud服务注册中心eureka---集群...
Java SE 第六章
HTTP请求+数据库
HIDL学习笔记之HIDL C++(第二天)
ubuntu系统下指定tomcat运行时为JDK1.8...
Play Framework Web开发教程 16 处理HTT...
copyright © 2008-2019 入门客AI创业平台 版权所有 备案号:
湘ICP备2023012770号