дёҖгҖҒе…ідәҺжҠ“еҢ…еҲҶжһҗе’Ңdebug LogдҝЎжҒҜ
жЁЎжӢҹзҷ»еҪ•и®ҝй—®йңҖиҰҒи®ҫзҪ®request headerдҝЎжҒҜпјҢеҜ№дәҺиҝҷдёӘжІЎжңүжҰӮеҝөзҡ„жңӢеҸӢеҸҜд»ҘеҸӮи§Ғжң¬зі»еҲ—еүҚйқўзҡ„javaзүҲзҲ¬иҷ«дёӯжҸҗеҲ°зҡ„жЁЎжӢҹзҷ»еҪ•иҝҮзЁӢпјҢдё»иҰҒе°ұжҳҜж·»еҠ иҜ·жұӮеӨҙrequest headerгҖӮ
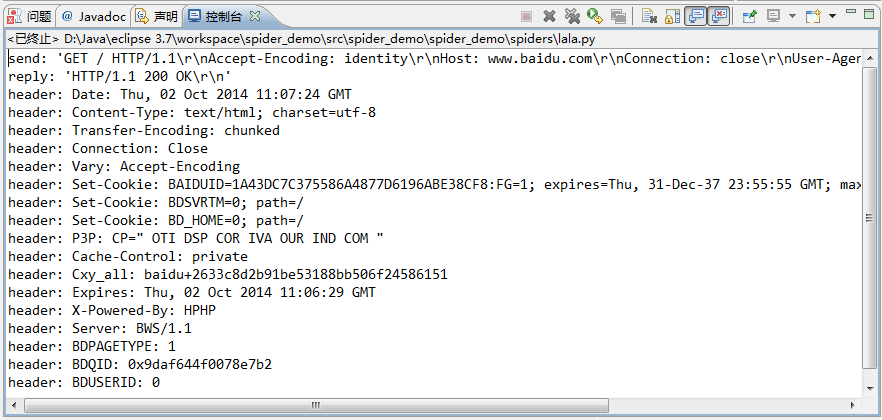
иҖҢpythonжҠ“еҢ…еҸҜд»ҘзӣҙжҺҘдҪҝз”Ёurllib2жҠҠdebug Logжү“ејҖпјҢж•°жҚ®еҢ…зҡ„еҶ…е®№еҸҜд»Ҙжү“еҚ°еҮәжқҘпјҢиҝҷж ·йғҪеҸҜд»ҘдёҚз”ЁжҠ“еҢ…дәҶпјҢзӣҙжҺҘеҸҜд»ҘзңӢеҲ°request headerйҮҢзҡ„еҶ…е®№гҖӮ
import urllib2 httpHandler = urllib2.HTTPHandler(debuglevel = 1) httpsHandler = urllib2.HTTPSHandler(debuglevel = 1) opener = urllib2.build_opener(httpHandler, httpsHandler) urllib2.install_opener(opener) response = urllib2.urlopen(вҖҳhttp://www.baidu.comвҖҷ) html = response.read()
еҸҰеӨ–еҜ№дәҺжҠ“еҢ…пјҢеҜ№жҜ”йҮҢеҗ„ж¬ҫжөҸи§ҲеҷЁиҮӘеёҰзҡ„ејҖеҸ‘иҖ…е·Ҙе…·пјҢи§үеҫ—firefoxзҡ„жҜ”Chromeзҡ„иҰҒеҘҪз”ЁпјҢдёҚд»…ж•°жҚ®еҢ…жҳҫзӨәжё…жҷ°пјҢиҖҢдё”еҗ„з§Қж“ҚдҪңд№ҹжҜ”Chromeзҡ„ж–№дҫҝеҫ—еӨҡпјҢиҝҳжңүдёҖдәӣChromeжІЎжңүзҡ„еҠҹиғҪгҖӮ
еҲҶжһҗдёӢзҷ»еҪ•ж–°жөӘеҫ®еҚҡиҝҮзЁӢзҡ„ж•°жҚ®еҢ…гҖӮ
зҷ»еҪ•еүҚйЎөйқўпјҡ
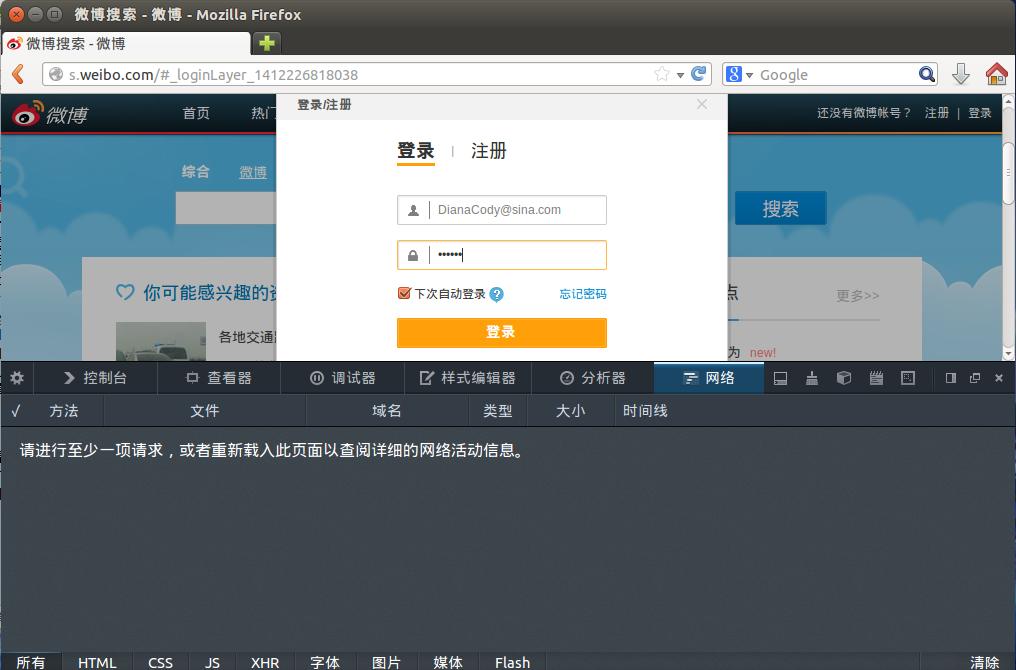
зӮ№еҮ»зҷ»еҪ•пјҢзңӢдёӢиҝҷдёӘиҝҮзЁӢпјҡ
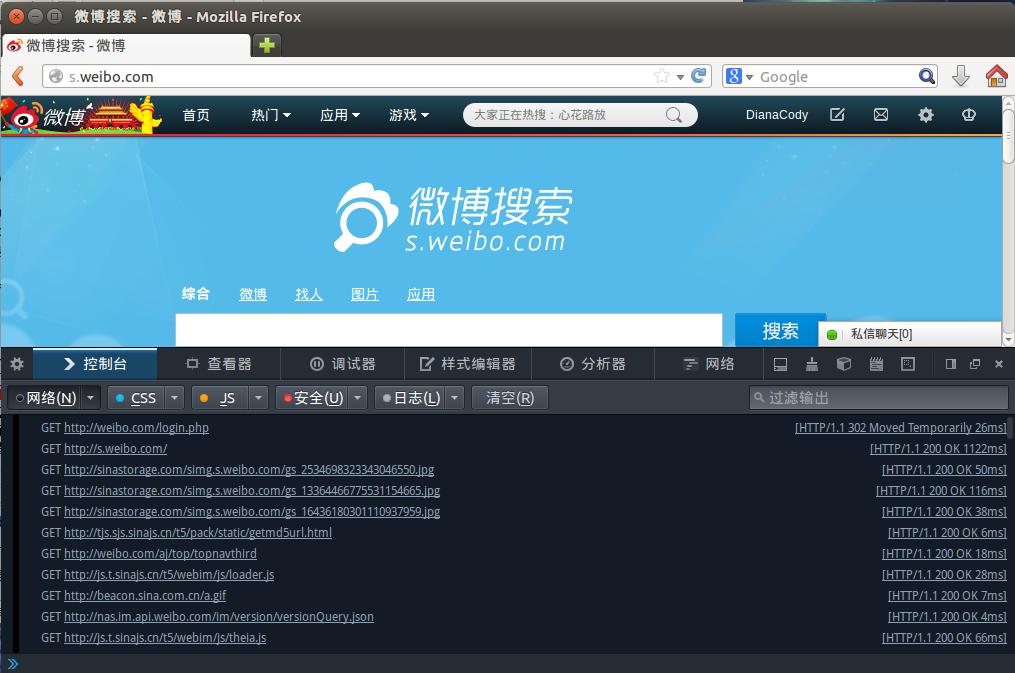
жү“ејҖзңӢж•°жҚ®еҢ…еҸҜд»ҘзңӢеҲ°иҜҰз»Ҷзҡ„иҜ·жұӮеӨҙгҖҒеҸ‘йҖҒCookieгҖҒе“Қеә”еӨҙгҖҒдј еӣһзҡ„ж–Ү件/ж•°жҚ®зӯүдҝЎжҒҜгҖӮ
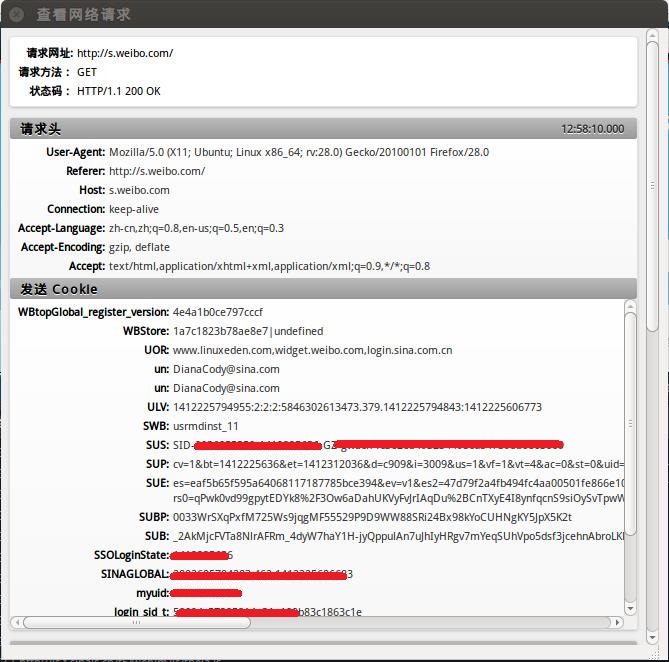
еңЁNetworkйҖүйЎ№еҚЎйҮҢзңӢзңӢиҜҰз»Ҷзҡ„жғ…еҶөпјҢиҝҷйҮҢжҳҜиҜ·жұӮеӨҙпјҡ
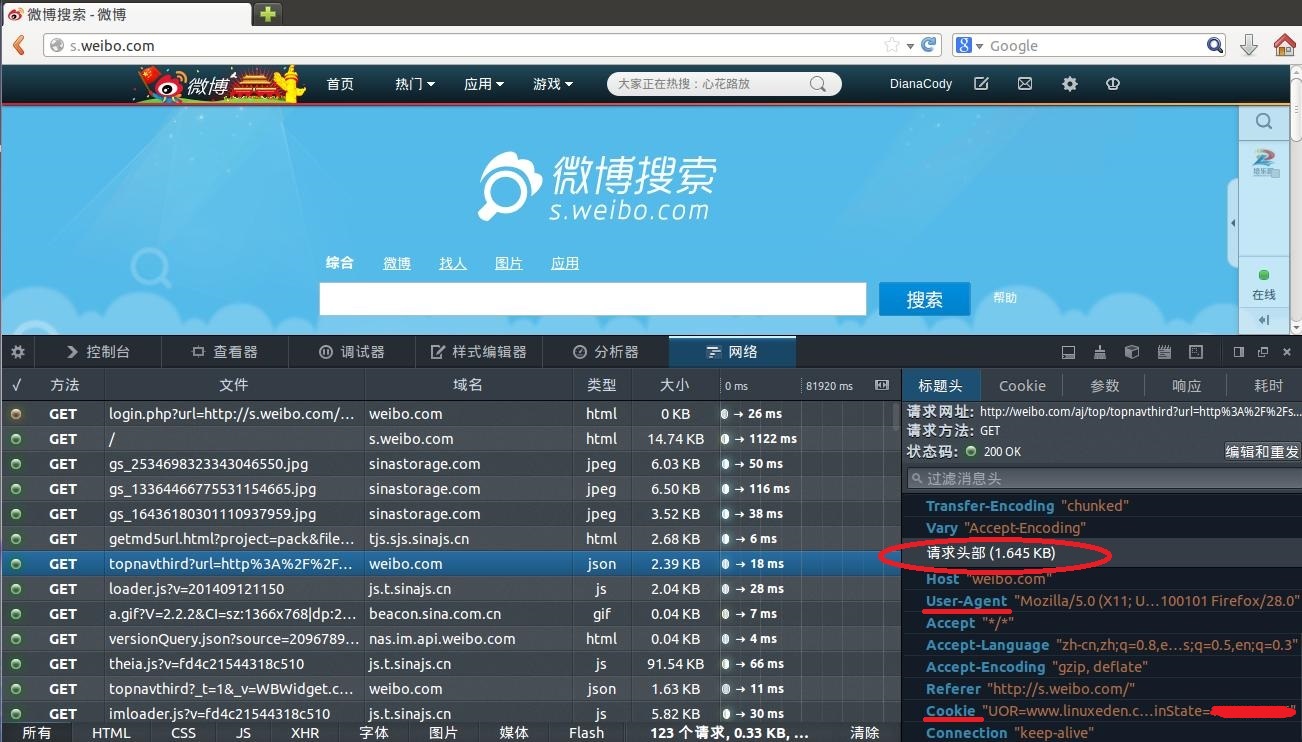
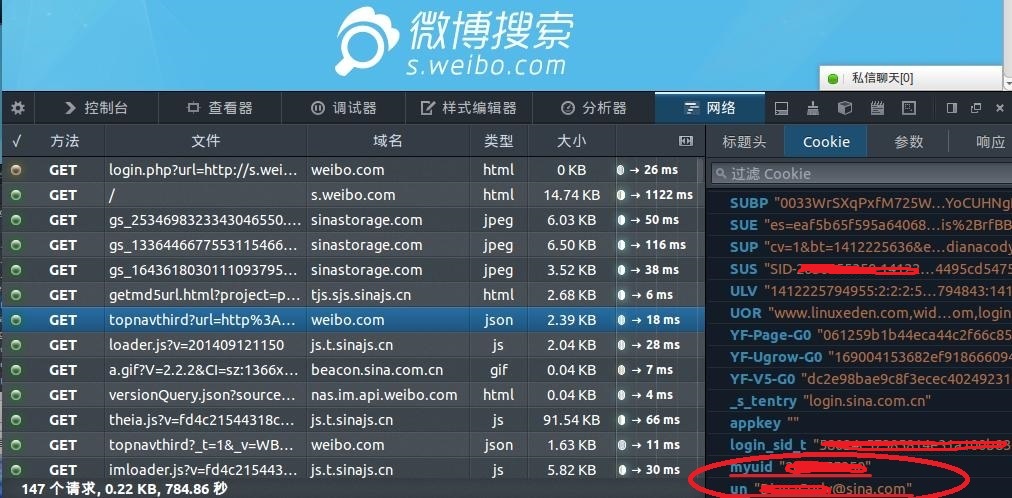
cookieеӯҳж”ҫзҡ„е°ұжҳҜmyuidе’ҢunиҙҰеҸ·пјҢд№ӢеҗҺжЁЎжӢҹзҷ»еҪ•иҰҒз”ЁеҲ°зҡ„cookieдҝЎжҒҜпјҡ
дәҢгҖҒи®ҫзҪ®HeadersеҲ°httpиҜ·жұӮ
е…ҲзңӢдёҖдёӘе®ҳж–№ж•ҷзЁӢдёҠзҡ„дҫӢеӯҗпјҡ
import urllib
import urllib2
url = "http://s.weibo.com"
user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11"
values = {"name":"denny",
"location":"BUPT",
"language":"Python"
}
headers = {"User-Agent":user_agent}
data = urllib.urlencode(values, 1)
request = urllib2.Request(url, data,headers)
response = urllib2.urlopen(request)
the_page = response.read()
print the_pageдёҖдёӘе®Ңж•ҙдҫӢеӯҗпјҡ
# -*- coding:utf8 -*-
import urllib2
import re
import StringIO
import gzip
ua = {#"User-Agent":"Mozilla/5.0 (compatible; Googlebot/2.1; +Googlebot - Webmaster Tools Help)",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36",
"Connection":"Keep-Alive",
"Accept-Language":"zh-CN,zh;q=0.8",
"Accept-Encoding":"gzip,deflate,sdch",
"Accept":"*/*",
"Accept-Charset":"GBK,utf-8;q=0.7,*;q=0.3",
"Cache-Control":"max-age=0"
}
def get_html(url_address):
"""open url and read it"""
req_http = urllib2.Request(url_address, headers = ua)
html = urllib2.urlopen(req_http).read()
return html
def controller():
"""make url list and download page"""
url = "http://s.weibo.com/wb/iPhone&nodup=1&page=10"
reget = re.compile("(<div class="post-wrapper.*?)<p class="pagination">", re.DOTALL)
fp = open("e:/weibo/head.txt", "w+")
for i in range(1, 131):
html_c = get_html(url % (i))
print url % (i)
html_c = gzip.GzipFile(fileobj = StringIO.StringIO(html_c)).read()
res = reget.findall(html_c)
for x in res:
fp.write(x)
fp.write("
")
fp.close()
return
if __name__ == "__main__":
controller()еҺҹеҲӣж–Үз« пјҢиҪ¬иҪҪиҜ·жіЁжҳҺеҮәеӨ„пјҡhttp://blog.csdn.net/dianacody/article/details/39742711
- дёҠдёҖзҜҮпјҡpythonзҪ‘жҳ“еҫ®еҚҡзҲ¬иҷ«иҪҜ件ејҖеҸ‘е®һдҫӢ
- дёӢдёҖзҜҮпјҡpythonзҪ‘з»ңзҲ¬иҷ«-scrapyзҲ¬иҷ«жЎҶжһ¶пјҲжһ¶жһ„гҖҒе®үиЈ…пјү
- ж–Үз« еҜјиҲӘ