
Spark Executor 报错 java.lang.StackOverflowError
前两天,一个同事在Hue中查询Hive中的一个大表,运行一分钟左右就报错了:

以及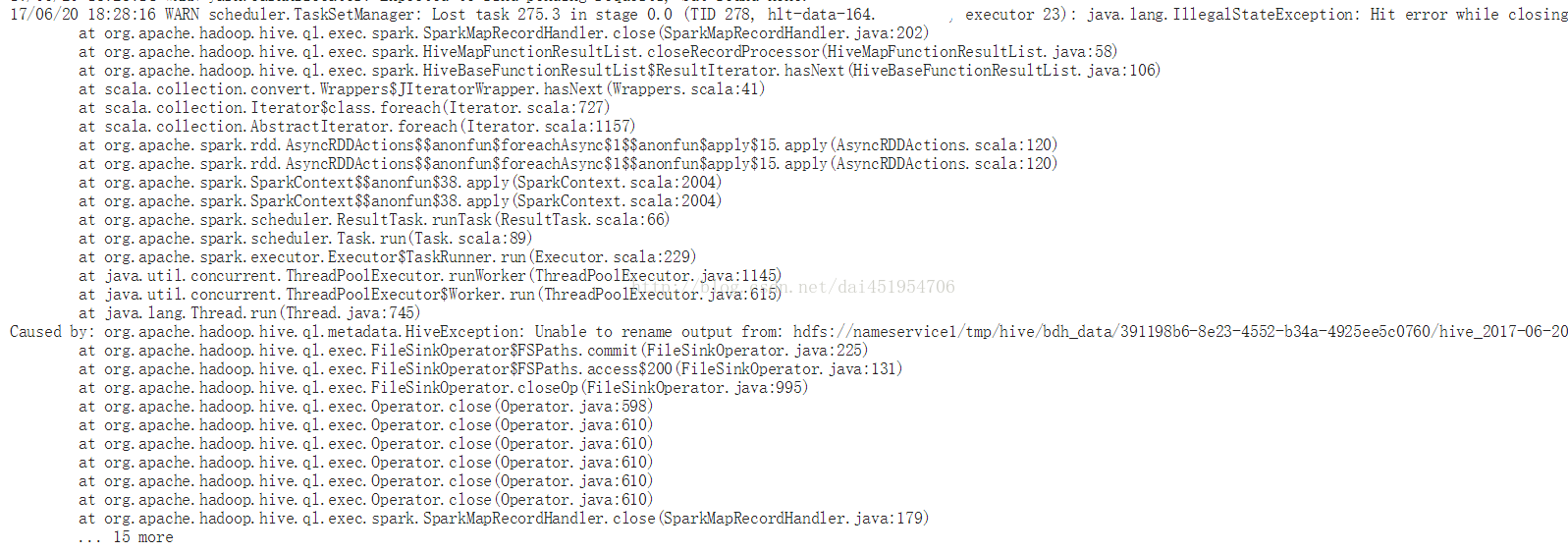

我尝试着去在spark-default.conf配置文件中添加(顺便也把GC回收的一些设置加上): spark.executor.extraJavaOptions=“-Xss4096k-XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintHeapAtGC -XX:+PrintGCApplicationConcurrentTime -Xloggc:gc.log" 以为这样应该就能解决问题了,谁知另外一些在使用spark的同事直接跟我说:spark-shell不能使用了。这挺奇怪的呀,我只是加了上面那一行设置,咋就不能正常执行了?我是我自己也进入spark-shell试试,果然直接报错了: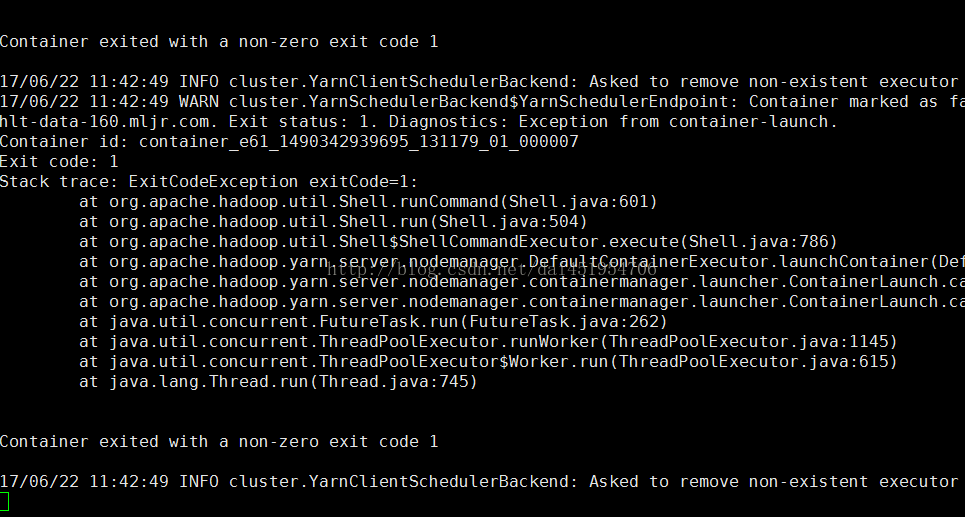
于是我根据终端的信息,找到了其中的一个Executor节点,进入到/opt/yarn/container-logs/目录下,也就是yarn存储container日志的目录,再根据container进入到对应目录下,查看stderr中记录的错误输出如下:
刚开始我以为是因为我多加了一些GC设置导致的,于是我只保留了 -Xss4096k,改为: spark.executor.extraJavaOptions=“-Xss4096k" 把其它设置都去除掉。再次进入Spark-shell,仍然包与之前一样的错误。我再次进入到container log目录下,查看stderr日志记录,这次报出来的是: Cann"t find main class. 这次的错误更加奇葩了,一时之间毫无头绪。 后来,突然想到,是不是不需要使用用双引号。于是我改成了: spark.executor.extraJavaOptions=-Xss4096k 改完后,再次进入spark-shell,一切恢复了正常。 接着我进入hive shell,执行了之前的HQL语句,可是错误依然存在。通过Spark WEB界面,进入到Environment页面,查看任务的相关环境设置,发现:
说明我改的spark-default.conf对于hive没有生效。 通过查阅hive资料,了解到需要把相应的设置加入到hive-site.xml配置文件中,于是我在hive-site.xml中加入了: <property> <name>spark.executor.extraJavaOptions</name> <value>-Xss4096k</value> </property> 再次进入hive shell,重新执行之前的HQL语句,运行了一分钟左右,终于得到了期盼已久的结果! 具体原因是: 由于Executor线程的栈满了,也就是函数调用层级过多导致,一般是递归调用的层级太多导致的。
- Error while processing statement: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask
以及
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to rename output from: hdfs://nameservice1/tmp/hive/bdh_data/391198b6-8e23-4552-b34a-4925ee5c0760/hive_2017-06-20_18-26-46_451_3402833551811264654-2/-mr-10000/ .hive-staging_hive_2017-06-20_18-26-46_451_3402833551811264654-2/_task_tmp.-ext-10001/_tmp.000275_0 to: hdfs://nameservice1/tmp/hive/bdh_data/391198b6-8e23-4552-b34a-4925ee5c0760/hive_2017-06-20_18-26-46_451_3402833551811264654-2/-mr-10000/ .hive-staging_hive_2017-06-20_18-26-46_451_3402833551811264654-2/_tmp.-ext-10001/000275_0刚开始我根据上面这一段错误信息去查找原因及解决方法,在这个页面(https://community.hortonworks.com/content/supportkb/49592/containers-logs-showing-tasks-that-are-unable-to-r.html) 中查到了类似的错误及解决方法,按照这上面说的原因是:由于在计算过程中将存放临时数据的目录删除了,导致计算完了之后重命名文件时报错。因此,需要查namenode日志,找到是什么原因导致目录被删除,并通过设置目录权限等方法来解决。 按照上面提供的思路去查找namenode日志,根本就没有找到上述目录的相关记录,而且在HDFS上检查对应的目录时,发现目录还是存在的,只是该目录下是空的。另外也有人说,是因为多个任务对HDF中的同一个文件同时进行读写导致的,不过这些方法都没有解决我的问题。 于是,我尝试着根据下面这几行错误进行查找:
17/06/21 18:24:41 ERROR executor.Executor: Exception in task 275.3 in stage 0.0 (TID 278) java.lang.StackOverflowErrorat java.util.concurrent.ConcurrentHashMap.hash(ConcurrentHashMap.java:333)at java.util.concurrent.ConcurrentHashMap.putIfAbsent(ConcurrentHashMap.java:1145) at java.lang.ClassLoader.getClassLoadingLock(ClassLoader.java:464)查阅了很多资料,有直接在Spark或者Hive项目中报Bug的,也有其它原因的。后来,在下面三个连接中找到了一些眉目: https://issues.apache.org/jira/browse/HIVE-10365 https://issues.apache.org/jira/browse/SPARK-18531 https://www.iteblog.com/archives/2151.html 尤其是第一个里面的回答:
我尝试着去在spark-default.conf配置文件中添加(顺便也把GC回收的一些设置加上): spark.executor.extraJavaOptions=“-Xss4096k-XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintHeapAtGC -XX:+PrintGCApplicationConcurrentTime -Xloggc:gc.log" 以为这样应该就能解决问题了,谁知另外一些在使用spark的同事直接跟我说:spark-shell不能使用了。这挺奇怪的呀,我只是加了上面那一行设置,咋就不能正常执行了?我是我自己也进入spark-shell试试,果然直接报错了:
于是我根据终端的信息,找到了其中的一个Executor节点,进入到/opt/yarn/container-logs/目录下,也就是yarn存储container日志的目录,再根据container进入到对应目录下,查看stderr中记录的错误输出如下:
刚开始我以为是因为我多加了一些GC设置导致的,于是我只保留了 -Xss4096k,改为: spark.executor.extraJavaOptions=“-Xss4096k" 把其它设置都去除掉。再次进入Spark-shell,仍然包与之前一样的错误。我再次进入到container log目录下,查看stderr日志记录,这次报出来的是: Cann"t find main class. 这次的错误更加奇葩了,一时之间毫无头绪。 后来,突然想到,是不是不需要使用用双引号。于是我改成了: spark.executor.extraJavaOptions=-Xss4096k 改完后,再次进入spark-shell,一切恢复了正常。 接着我进入hive shell,执行了之前的HQL语句,可是错误依然存在。通过Spark WEB界面,进入到Environment页面,查看任务的相关环境设置,发现:
说明我改的spark-default.conf对于hive没有生效。 通过查阅hive资料,了解到需要把相应的设置加入到hive-site.xml配置文件中,于是我在hive-site.xml中加入了: <property> <name>spark.executor.extraJavaOptions</name> <value>-Xss4096k</value> </property> 再次进入hive shell,重新执行之前的HQL语句,运行了一分钟左右,终于得到了期盼已久的结果! 具体原因是: 由于Executor线程的栈满了,也就是函数调用层级过多导致,一般是递归调用的层级太多导致的。
声明:该文观点仅代表作者本人,入门客AI创业平台信息发布平台仅提供信息存储空间服务,如有疑问请联系rumenke@qq.com。
