
理解线程池的原理
读完本文你将了解:
- 什么是线程池
- 线程池的处理流程
- 保存待执行任务的阻塞队列
- 创建自己的线程池
- JDK 提供的线程池及使用场景
- newFixedThreadPool
- newSingleThreadExecutor
- newCachedThreadPool
- newScheduledThreadPool
- 两种提交任务的方法
- execute
- submit
- 关闭线程池
- 如何合理地选择或者配置
- 总结
- Thanks
线程池的概念大家应该都很清楚,帮我们重复管理线程,避免创建大量的线程增加开销。
除了降低开销以外,线程池也可以提高响应速度,了解点 JVM 的同学可能知道,一个对象的创建大概需要经过以下几步:
- 检查对应的类是否已经被加载、解析和初始化
- 类加载后,为新生对象分配内存
- 将分配到的内存空间初始为 0
- 对对象进行关键信息的设置,比如对象的哈希码等
- 然后执行 init 方法初始化对象
创建一个对象的开销需要经过这么多步,也是需要时间的嘛,那可以复用已经创建好的线程的线程池,自然也在提高响应速度上做了贡献。
创建线程池需要使用 ThreadPoolExecutor 类,它的构造函数参数如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
参数介绍如注释所示,要了解这些参数左右着什么,就需要了解线程池具体的执行方法ThreadPoolExecutor.execute:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
可以看到,线程池处理一个任务主要分三步处理,代码注释里已经介绍了,我再用通俗易懂的例子解释一下:
(线程比作员工,线程池比作一个团队,核心池比作团队中核心团队员工数,核心池外的比作外包员工)
- 有了新需求,先看核心员工数量超没超出最大核心员工数,还有名额的话就新招一个核心员工来做
- 需要获取全局锁
- 核心员工已经最多了,HR 不给批 HC 了,那这个需求只好攒着,放到待完成任务列表吧
- 如果列表已经堆满了,核心员工基本没机会搞完这么多任务了,那就找个外包吧
- 需要获取全局锁
- 如果核心员工 + 外包员工的数量已经是团队最多能承受人数了,没办法,这个需求接不了了
结合这张图,这回流程你明白了吗?
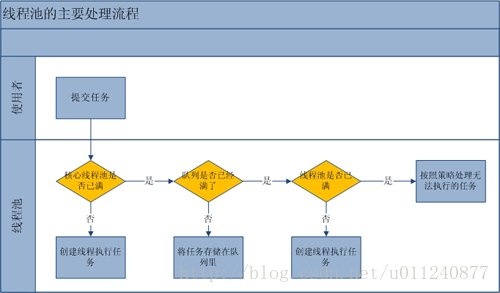
由于 1 和 3 新建线程时需要获取全局锁,这将严重影响性能。因此 ThreadPoolExecutor 这样的处理流程是为了在执行 execute() 方法时尽量少地执行
1 和 3,多执行 2。
在
ThreadPoolExecutor完成预热后(当前线程数不少于核心线程数),几乎所有的execute()都是在执行步骤 2。
前面提到的 ThreadPoolExecutor 构造函数的参数,分别影响以下内容:
corePoolSize:核心线程池数量
- 在线程数少于核心数量时,有新任务进来就新建一个线程,即使有的线程没事干
- 等超出核心数量后,就不会新建线程了,空闲的线程就得去任务队列里取任务执行了
maximumPoolSize:最大线程数量
- 包括核心线程池数量 + 核心以外的数量
- 如果任务队列满了,并且池中线程数小于最大线程数,会再创建新的线程执行任务
keepAliveTime:核心池以外的线程存活时间,即没有任务的外包的存活时间
- 如果给线程池设置
allowCoreThreadTimeOut(true),则核心线程在空闲时头上也会响起死亡的倒计时 - 如果任务是多而容易执行的,可以调大这个参数,那样线程就可以在存活的时间里有更大可能接受新任务
- 如果给线程池设置
workQueue:保存待执行任务的阻塞队列
- 不同的任务类型有不同的选择,下一小节介绍
threadFactory:每个线程创建的地方
- 可以给线程起个好听的名字,设置个优先级啥的
handler:饱和策略,大家都很忙,咋办呢,有四种策略
CallerRunsPolicy:只要线程池没关闭,就直接用调用者所在线程来运行任务AbortPolicy:直接抛出RejectedExecutionException异常DiscardPolicy:悄悄把任务放生,不做了DiscardOldestPolicy:把队列里待最久的那个任务扔了,然后再调用execute()试试看能行不- 我们也可以实现自己的
RejectedExecutionHandler接口自定义策略,比如如记录日志什么的
当线程池中的核心线程数已满时,任务就要保存到队列中了。
线程池中使用的队列是 BlockingQueue 接口,常用的实现有如下几种:
- ArrayBlockingQueue:基于数组、有界,按 FIFO(先进先出)原则对元素进行排序
- LinkedBlockingQueue:基于链表,按FIFO (先进先出) 排序元素
- 吞吐量通常要高于 ArrayBlockingQueue
- Executors.newFixedThreadPool() 使用了这个队列
- SynchronousQueue:不存储元素的阻塞队列
- 每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态
- 吞吐量通常要高于 LinkedBlockingQueue
- Executors.newCachedThreadPool使用了这个队列
- PriorityBlockingQueue:具有优先级的、无限阻塞队列
关于阻塞队列的详细介绍请看这篇:
了解上面的内容后,我们就可以创建自己的线程池了。
①先定义线程池的几个关键属性的值:
- 1
- 2
- 3
- 1
- 2
- 3
- 设置核心池的数量为 CPU 数的两倍,一般是 4、8,好点的 16 个线程
- 最大线程数设置为 64
- 空闲线程的存活时间设置为 1 秒
②然后根据处理的任务类型选择不同的阻塞队列
如果是要求高吞吐量的,可以使用 SynchronousQueue 队列;如果对执行顺序有要求,可以使用 PriorityBlockingQueue;如果最大积攒的待做任务有上限,可以使用 LinkedBlockingQueue。
- 1
- 1
③然后创建自己的 ThreadFactory
在其中为每个线程设置个名称:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
④然后就可以创建线程池了
- 1
- 2
- 3
- 1
- 2
- 3
这里我们选择的饱和策略为 DiscardOldestPolicy,你可以可以创建自己的。
⑤完整代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
这样我们就有了自己的线程池。
JDK 为我们内置了五种常见线程池的实现,均可以使用 Executors 工厂类创建。
1.newFixedThreadPool
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
不招外包,有固定数量核心成员的正常互联网团队。
可以看到,FixedThreadPool 的核心线程数和最大线程数都是指定值,也就是说当线程池中的线程数超过核心线程数后,任务都会被放到阻塞队列中。
此外 keepAliveTime 为 0,也就是多余的空余线程会被立即终止(由于这里没有多余线程,这个参数也没什么意义了)。
而这里选用的阻塞队列是 LinkedBlockingQueue,使用的是默认容量 Integer.MAX_VALUE,相当于没有上限。
因此这个线程池执行任务的流程如下:
- 线程数少于核心线程数,也就是设置的线程数时,新建线程执行任务
- 线程数等于核心线程数后,将任务加入阻塞队列
- 由于队列容量非常大,可以一直加加加
- 执行完任务的线程反复去队列中取任务执行
FixedThreadPool 用于负载比较重的服务器,为了资源的合理利用,需要限制当前线程数量。
2.newSingleThreadExecutor
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
不招外包,只有一个核心成员的创业团队。
从参数可以看出来,SingleThreadExecutor 相当于特殊的 FixedThreadPool,它的执行流程如下:
- 线程池中没有线程时,新建一个线程执行任务
- 有一个线程以后,将任务加入阻塞队列,不停加加加
- 唯一的这一个线程不停地去队列里取任务执行
听起来很可怜的样子 - -。
SingleThreadExecutor 用于串行执行任务的场景,每个任务必须按顺序执行,不需要并发执行。
3.newCachedThreadPool
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
全部外包,没活最多待 60 秒的外包团队。
可以看到,CachedThreadPool 没有核心线程,非核心线程数无上限,也就是全部使用外包,但是每个外包空闲的时间只有 60 秒,超过后就会被回收。
CachedThreadPool 使用的队列是 SynchronousQueue,这个队列的作用就是传递任务,并不会保存。
因此当提交任务的速度大于处理任务的速度时,每次提交一个任务,就会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。
它的执行流程如下:
- 没有核心线程,直接向
SynchronousQueue中提交任务 - 如果有空闲线程,就去取出任务执行;如果没有空闲线程,就新建一个
- 执行完任务的线程有 60 秒生存时间,如果在这个时间内可以接到新任务,就可以继续活下去,否则就拜拜
由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。
CachedThreadPool 用于并发执行大量短期的小任务,或者是负载较轻的服务器。
4.newScheduledThreadPool
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
定期维护的 2B 业务团队,核心与外包成员都有。
ScheduledThreadPoolExecutor 继承自 ThreadPoolExecutor,
最多线程数为 Integer.MAX_VALUE ,使用 DelayedWorkQueue 作为任务队列。
ScheduledThreadPoolExecutor 添加任务和执行任务的机制与ThreadPoolExecutor 有所不同。
ScheduledThreadPoolExecutor 添加任务提供了另外两个方法:
scheduleAtFixedRate():按某种速率周期执行scheduleWithFixedDelay():在某个延迟后执行
它俩的代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 上一篇:没有了
- 下一篇: shiro原理及其运行流程介绍
